🔍 Overview
- Medications: Patients prescribed a higher number of medications exhibited an increased likelihood of readmission.
Recommendation: Implement robust medication review and management protocols to mitigate risks. - Recent Hospitalizations: Hospitalizations within the past 30 days strongly predicted readmission.
Recommendation: Enhance post-discharge follow-up care to monitor high-risk patients. - Primary Care Engagement: Patients with fewer appointments with their primary care physicians showed higher readmission rates.
Recommendation: Strengthen outpatient engagement and promote routine check-ups.
- 65+ Patients: Patients aged 65 and older presented the highest readmission rates. (ANOVA P-value < 0.01)
Recommendation: Prioritize proactive intervention programs, including discharge planning and geriatric-specific monitoring, for this demographic.
- Correlation: A moderate positive correlation (Pearson coefficient: 0.46) was found between hospital stay duration and readmission likelihood.
Recommendation: Provide personalized care transitions for patients requiring extended hospital stays to minimize risks.
- Kaplan-Meier Results: The average time to readmission was 26.3 days, with 36% of readmissions occurring within the first 30 days post-discharge.
Recommendation: Focus early intervention efforts during this critical period to reduce readmission rates and improve patient outcomes.
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# Calculate ROC Curve
fpr, tpr, _ = roc_curve(y_test, y_pred_final)
roc_auc = auc(fpr, tpr)
# Plot the ROC Curve
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # Diagonal line for random guessing
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()We used model stacking to combine the predictions from both the numerical features and the text data. By integrating the outputs of the Logistic Regression model (based on TF-IDF) with the numerical features, we improved the overall predictive power. The stacked model utilized a Random Forest classifier for the final prediction:
We used model stacking to combine the predictions from both the numerical features and the text data. By integrating the outputs of the Logistic Regression model (based on TF-IDF) with the numerical features, we improved the overall predictive power. The stacked model utilized a Random Forest classifier for the final prediction:
We used model stacking to combine the predictions from both the numerical features and the text data. By integrating the outputs of the Logistic Regression model (based on TF-IDF) with the numerical features, we improved the overall predictive power. The stacked model utilized a Random Forest classifier for the final prediction:
We used model stacking to combine the predictions from both the numerical features and the text data. By integrating the outputs of the Logistic Regression model (based on TF-IDF) with the numerical features, we improved the overall predictive power. The stacked model utilized a Random Forest classifier for the final prediction:
1. 🛠️ Data Preprocessing
Before building the model, we performed the following preprocessing steps:
-
Columns with excessive missing values (e.g., `max_glu_serum`) were removed.
- Categorical columns were encoded using Label Encoding and One-Hot Encoding.
- Numerical columns were standardized using `StandardScaler` to normalize the data.
- Binary columns like `change` and `diabetesMed` were mapped to `0` (No) and `1` (Yes).
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler
df.replace("?", np.nan, inplace=True) # Replace '?' with NaN
df['discharge_disposition_id'].fillna('Unknown', inplace=True)
df['admission_source_id'].fillna('Not Mapped', inplace=True)
df['medical_specialty'].fillna('Unknown', inplace=True)
df['payer_code'].fillna('Unknown', inplace=True)
df.drop(columns=['max_glu_serum'], inplace=True)
le = LabelEncoder()
df['discharge_disposition_id'] = le.fit_transform(df['discharge_disposition_id'])
df['admission_source_id'] = le.fit_transform(df['admission_source_id'])
df['payer_code'] = le.fit_transform(df['payer_code'])
df['medical_specialty'] = le.fit_transform(df['medical_specialty'])
scaler = StandardScaler()
df_numeric = df.select_dtypes(include=np.number)
df_numeric_scaled = scaler.fit_transform(df_numeric)Correlation Analysis with Heatmap: To identify relationships between numerical features, we used a heatmap to visualize correlations between them.
import matplotlib.pyplot as plt
import seaborn as sns
# Calculate the correlation matrix for numerical features
corr_matrix = df_numeric.corr()
# Plot the heatmap for correlations
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, cmap='RdYlBu', annot=True, fmt=".2f")
plt.title('Correlation Heatmap of Numerical Features')
plt.show()From the heatmap, the value of 0.43 indicates a moderate positive correlation between num_medications and num_procedures
2.📊 Exploratory Data Analysis (EDA)
We conducted a detailed analysis of the dataset to understand the distribution of the target variable and to identify correlations between numerical features. Visualizations like bar plots and heatmaps helped in this process.
Target Variable Distribution
The target variable readmitted showed an imbalance, with approximately 60% of patients not being readmitted and 40% being readmitted. This imbalance informed the model selection process.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(6, 4)) # Visualize the target variable distribution
sns.countplot(x='readmitted', data=df)
plt.title('Distribution of Readmitted Patients')
plt.xlabel('Readmitted')
plt.ylabel('Count')
plt.show()We experimented with multiple machine learning models to determine which performed best on this dataset. These included:
- Decision Tree: A simple and interpretable model, but prone to overfitting.
- Random Forest: An ensemble method that improves performance by reducing overfitting.
- Gradient Boosting: A powerful method that outperformed simpler models.
- XGBoost: The final selected model, known for its scalability and accuracy. Each model was evaluated using the ROC AUC score to compare their predictive performance.
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
# Split the dataset into training and testing sets
X = df_numeric_scaled
y = df['readmitted'].apply(lambda x: 1 if x else 0) # Binary target label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
# Train a Random Forest model
clf = RandomForestClassifier(min_samples_split=90, min_samples_leaf=5, max_depth=10, random_state=10)
clf.fit(X_train, y_train)
# Predict using the test set
y_pred = clf.predict_proba(X_test)[:, 1]
# Calculate the ROC AUC score
roc_auc = roc_auc_score(y_test, y_pred)
print(f'ROC AUC: {roc_auc:.2f}')The dataset included a text-based field ai_response. To incorporate this, we used TF-IDF (Term Frequency-Inverse Document Frequency) to convert the text data into numerical features. Logistic Regression was applied to the text data to predict readmission probabilities.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# Set up the TF-IDF vectorizer and fit it on the training text data
tfidf = TfidfVectorizer(ngram_range=(1, 3), max_features=1500)
X_train_text = tfidf.fit_transform(df_train['ai_response'])
# Train a Logistic Regression model using text data
clf_text = LogisticRegression(max_iter=2000)
clf_text.fit(X_train_text, y_train)
# Predict probabilities on the test text data
X_test_text = tfidf.transform(df_test['ai_response'])
y_pred_text = clf_text.predict_proba(X_test_text)[:, 1]We used model stacking to combine the predictions from both the numerical features and the text data. By integrating the outputs of the Logistic Regression model (based on TF-IDF) with the numerical features, we improved the overall predictive power. The stacked model utilized a Random Forest classifier for the final prediction:
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# Calculate ROC Curve
fpr, tpr, _ = roc_curve(y_test, y_pred_final)
roc_auc = auc(fpr, tpr)
# Plot the ROC Curve
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # Diagonal line for random guessing
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()6. 📊 Results and ROC Curve Visualization
The final model, XGBoost, achieved an ROC AUC score of 0.68 on the test dataset. Below is the ROC Curve, which demonstrates the model’s ability to distinguish between positive and negative classes:
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# Calculate ROC Curve
fpr, tpr, _ = roc_curve(y_test, y_pred_final)
roc_auc = auc(fpr, tpr)
# Plot the ROC Curve
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # Diagonal line for random guessing
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show() 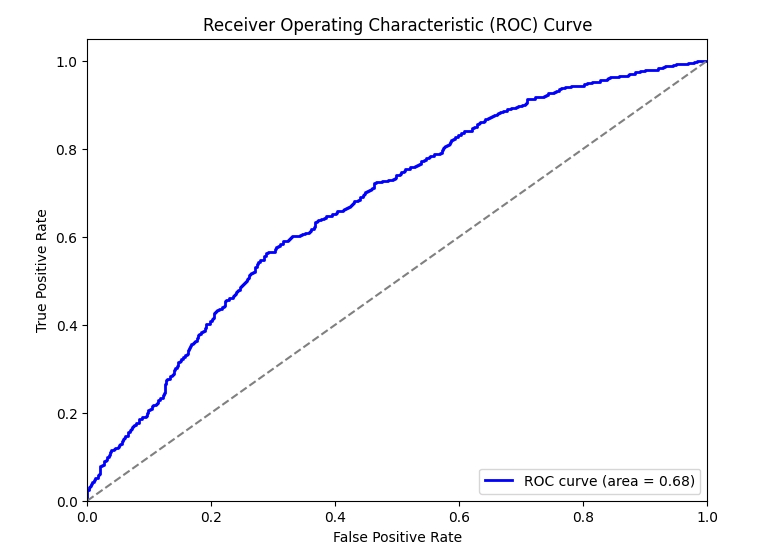
The final model selected was XGBoost, achieving an ROC AUC score of 0.68 on the test data. This result shows a reasonable ability to predict patient readmission, though there is room for improvement. The inclusion of text data via TF-IDF combined with numerical features using model stacking contributed to a more accurate prediction.