
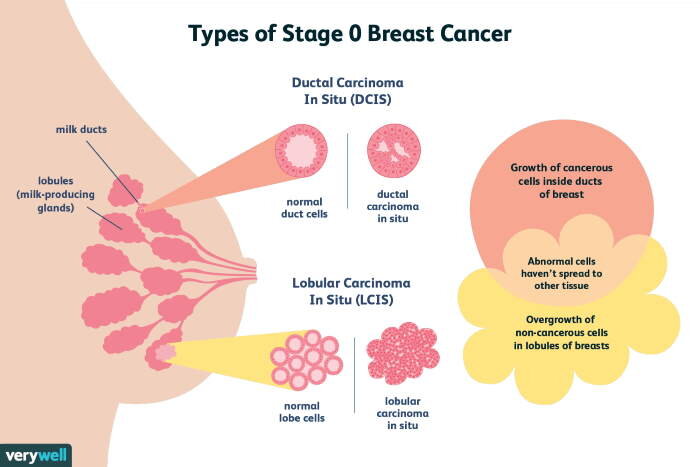


3. SVD Clustering:
- A similar visualization is provided after applying SVD for dimensionality reduction, showing that the clusters remain well-separated even after reducing the dataset’s dimensionality by 15x.

Korean Medicine Doctor
Data Scientist
Data Analyst
Korean Medicine Doctor
Data Scientist
Data Analyst